VECTOR - VECTOR Encodes Coordinates To Optimize Retrieval
A lightweight vector database library for Python that brings mathematical elegance to data organization. VECTOR organizes data using coordinate systems, where every table has an X-axis as the primary key and other attributes represent relationships between dimensional spaces.
The Mathematical Foundation
Vector database design is inspired by mathematical vector spaces. Data points exist as vectors in a coordinate space, with the X-axis serving as the primary coordinate system and other dimensions representing the vector’s components in different spaces.
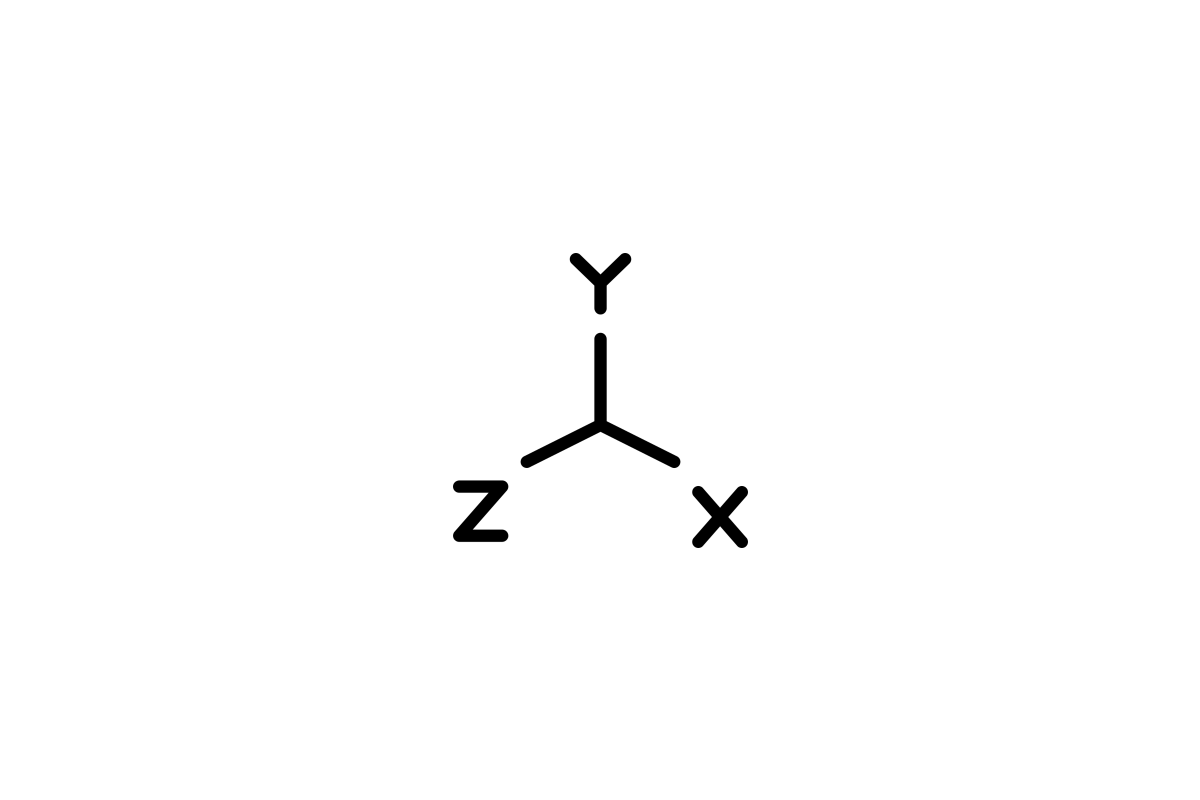
The coordinate system architecture creates a natural model where:
- X-axis (Central Axis): Primary key and coordinate system foundation
- Y, Z, J… (Dimensional Spaces): Additional attributes that define relationships
- Coordinate Mappings: Functions that map between dimensional spaces
- Vector Points: Individual data records positioned in the coordinate space
Key Features
Vector Mathematics Foundation
The architecture is built on mathematical coordinate principles:
- Coordinate System Architecture: Data organized around mathematical coordinate principles
- Dimensional Spaces: Scalable N-dimensional data representation without structural changes
- O(1) Lookup Performance: Coordinate indexing enables instant data retrieval
- Value Deduplication: Automatic storage optimization through value deduplication in dimensional spaces
Domain-Driven Architecture
The codebase follows clean architecture principles:
- Clean Architecture: Separation of domain logic, application services, and infrastructure
- Coordinate Abstractions: Rich domain objects representing mathematical concepts
- Immutable Value Objects: Thread-safe coordinate and mapping representations
- Repository Patterns: Clean data access interfaces
Performance Optimizations
VECTOR is designed for efficiency:
- MessagePack Serialization: Much smaller files than JSON
- Gzip Compression: Additional compression for minimal overhead
- File Locking: Multi-process safety with automatic lock management
- LRU Caching: In-memory caching for frequently accessed data
- Context Managers: Automatic resource management and cleanup
Clean API Design
The API is designed to be intuitive and Pythonic:
from vector_datalib import VectorDB
# Create database with context manager
with VectorDB("my_data.db") as db:
# Insert data with automatic collision detection
db.insert(101, {"age": 25, "name": "Alice"})
db.insert(102, {"age": 30, "name": "Bob"})
db.insert(103, {"age": 25, "name": "Charlie"}) # age=25 deduplicated
# O(1) coordinate-based lookup
name = db.lookup(101, "name")
print(f"Employee 101: {name}") # Employee 101: Alice
# Batch operations for efficiency
db.batch_insert([
(104, {"name": "Diana", "age": 28}),
(105, {"name": "Eve", "age": 32}),
(106, {"name": "Frank", "age": 27})
])
# Update operations
db.update(101, "age", 26)
Architecture Layers
VECTOR follows clean architecture principles with three distinct layers:
Domain Layer
- CentralAxis: Manages X-coordinate system and primary key constraints
- DimensionalSpace: Handles Y, Z, J… dimensions with value deduplication
- CoordinateMapping: Maps relationships between dimensional spaces
- VectorPoint: Represents individual data records as coordinate positions
Application Layer
- VectorDB: Main database interface providing the scripting API
- Coordinate Operations: Insert, lookup, update operations on coordinate system
- Dimensional Management: Dynamic expansion and contraction of coordinate spaces
Infrastructure Layer
- VectorFileStorage: Handles .db file format with JSON and gzip compression
- Persistence Management: Atomic save/load operations with metadata
Mathematical Model
Coordinate System Design
All tables follow the coordinate system principle:
- X-axis (Primary Key): Central coordinate that uniquely identifies each vector point
- Dimensional Relationships: Other attributes represent relationships between the X-coordinate and various dimensional spaces
# Mathematical representation:
Point P at coordinate X has relationships to multiple dimensions
P(x) = {Y: f_y(x), Z: f_z(x), J: f_j(x), ...}
Value Deduplication
VECTOR automatically optimizes storage by deduplicating values within dimensional spaces:
db.insert(101, {"age": 25, "name": "Alice"})
db.insert(102, {"age": 25, "name": "Bob"}) # age=25 stored once
db.insert(103, {"age": 25, "name": "Charlie"}) # age=25 referenced
N-Dimensional Scalability
Add new dimensions without structural changes:
# Start with 2 dimensions
db.insert(101, {"age": 25, "name": "Alice"})
# Expand to 3 dimensions
db.insert(102, {"age": 30, "name": "Bob", "city": "Boston"})
# Expand to N dimensions dynamically
db.insert(103, {"age": 25, "name": "Charlie", "city": "Boston", "department": "Engineering"})
Performance Characteristics
Time Complexity
- Insert: O(1) average case with hash-based coordinate indexing
- Lookup: O(1) direct coordinate access
- Update: O(1) coordinate-based modification
- Dimensional Expansion: O(1) addition of new coordinate relationships
Storage Optimizations
The file format uses MessagePack serialization with gzip compression, resulting in 2-3x smaller files than JSON while maintaining fast access times. The LRU caching system ensures frequently accessed data is retrieved instantly.
Practical Applications
User Management System
with VectorDB("users.db") as db:
# X-coordinate: User ID, Y-dimension: Profile data
db.insert(1001, {"name": "Alice Johnson", "age": 28, "department": "Engineering"})
# O(1) user lookup
name = db.lookup(1001, "name")
age = db.lookup(1001, "age")
# Dynamic expansion - add new dimensional relationships
db.update(1001, "salary", 75000)
db.update(1001, "location", "Boston")
Product Catalog
with VectorDB("products.db") as db:
# X-coordinate: Product ID, Y/Z dimensions: Product attributes
db.insert(2001, {"name": "Laptop", "price": 999.99, "category": "Electronics"})
# Value deduplication automatically optimizes "Electronics" category storage
Design Philosophy
VECTOR is built for developers who appreciate clean architecture and mathematical elegance. The coordinate-based approach provides:
- Mathematical Precision: Data organization based on proven coordinate system theory
- Clean Code: Domain-driven design with clear separation of concerns
- Scalability: N-dimensional growth without architectural changes
- Performance: O(1) operations with intelligent caching and deduplication
Getting Started
Installation is simple:
# Clone the repository
git clone https://github.com/domasles/vector.git
cd vector
# Install in development mode
pip install -e .
Requirements:
- Python 3.9+
- Dependencies: msgpack, filelock (for binary serialization and file locking)
The Vector Vision
The name “Vector” reflects the mathematical foundation where data points exist as vectors in a coordinate space. The X-axis serves as the primary coordinate system, and other dimensions represent the vector’s components in different spaces.
This approach provides:
- Coordinates define position: X-axis establishes the coordinate system foundation
- Dimensions represent relationships: Each dimension shows how data relates to coordinates
- Mappings preserve structure: Functions between dimensions maintain mathematical consistency
- Scalability through expansion: N-dimensional growth without architectural changes
VECTOR demonstrates that database design can be both mathematically elegant and practically efficient, combining O(1) performance with clean architecture principles.
Conclusion
VECTOR proves that applying mathematical rigor to software design creates tools that are both powerful and understandable. By embracing coordinate system principles and clean architecture, it provides a database solution that developers can truly comprehend and extend.
Whether you’re building a simple data store, exploring database internals, or need a lightweight solution for embedded systems, VECTOR offers a foundation built on mathematical precision rather than hidden complexity.
The library shows that elegant design doesn’t require sacrificing performance - coordinate-based organization naturally enables O(1) operations while maintaining code clarity and architectural cleanliness.
Explore the source code, experiment with the examples, and discover how mathematical principles can transform data organization.





{kind=link}